As a psychology researcher conducting experiments online, you want to make sure that your participants are acting in good faith. Opportunistic participants signing up for research platforms just to exploit their reward systems can threaten the quality of your data. Most high-quality participant pools (including Testable Minds) have mechanisms in place to identify and penalize participants who consistently act in bad faith. And of course, you can always exclude unfit data from your analysis. But this process can be tedious and add unnecessary time to your fieldwork.
In this article, we’ll cover some proven tactics for discouraging participants from acting in taking advantage of your experiments; or at least make it easier for you to identify them in your data analysis.
For experiments that track accuracy (and reaction times), it can be a good idea to implement feedback throughout the experiment. During initial trials, it might be a good idea to give feedback for both correct and incorrect responses. To keep the experiment lean, you might instead present feedback only for incorrect trials. This way, participants have the incentive to perform as best as they can to get through the experiment quickly.
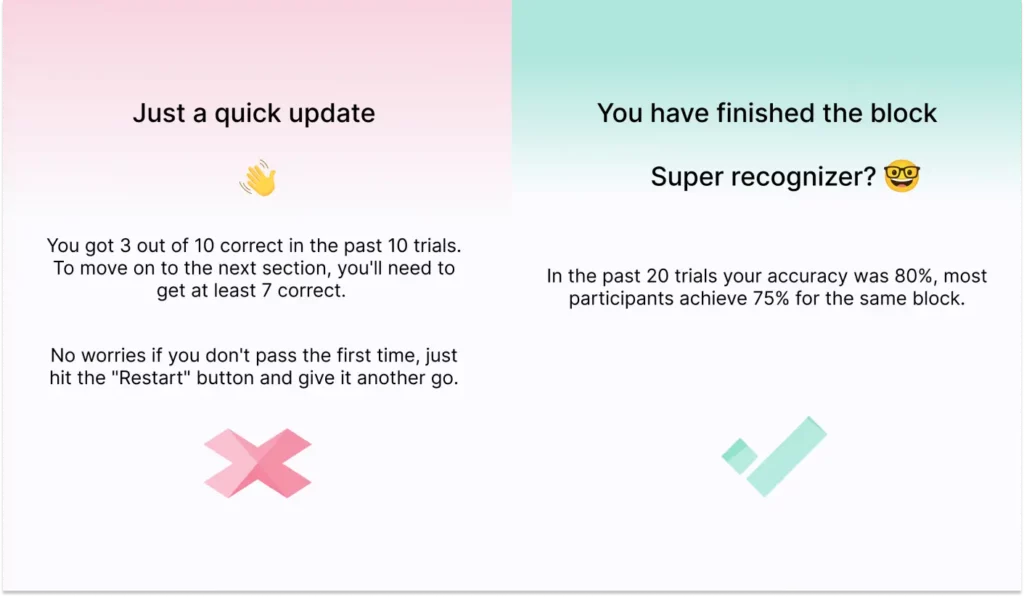
If trial-by-trial feedback is impractical, you can instead implement feedback at the end of larger blocks of trials.
Example: “In the past 20 trials your accuracy was 60%, most participants achieve 75% for the same block”.
Using advanced logic you can even restrict progression to the next stage of the experiment based on performance. This can be a very effective tool to both encourage participants to prevent cheating as well as push their performance. However, we suggest that you do sufficient testing to calibrate the appropriate performance thresholds for your experiment. It is important to never prevent participants from completing an experiment based on their performance alone.
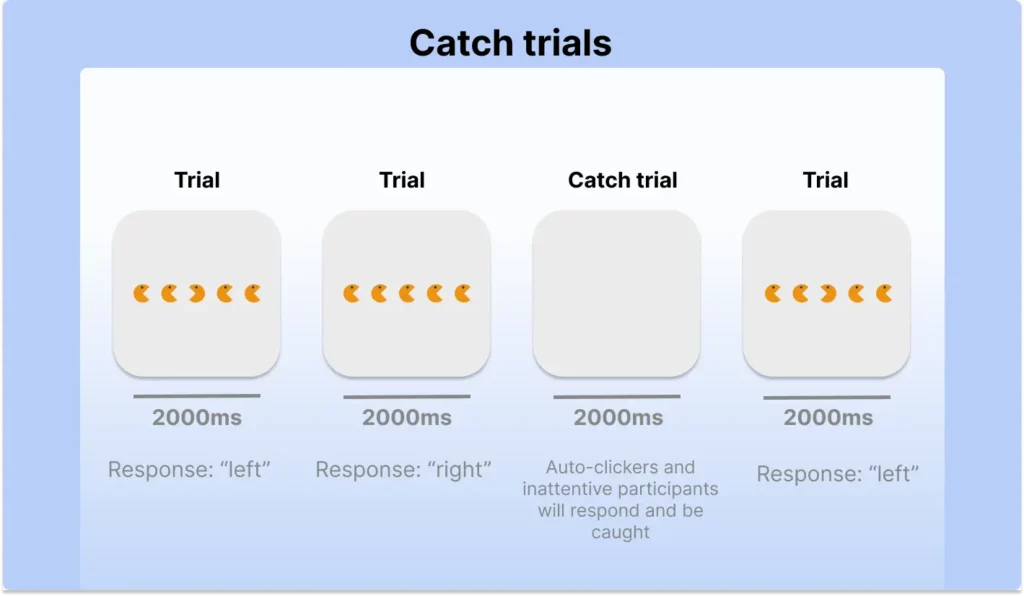
A catch trial is an unexpected or misleading item that is presented among the other items in the experiment. A simple catch trial could be one where no stimulus is presented at all, but responses would still be recorded. Participants who were not paying attention would be more likely to make errors on the catch trial. This could be used to identify inattentive participants and exclude their data from the analysis. You can also ask easy questions like “How many letters does the word “dog” have?” in between experiment trials.
This is a simple relatively non-intrusive way to encourage participants to pay full attention and discourage cheating. Ideally, you plant a catch trial early in the experiment and follow it up with a 10-second unskippable penalty screen. This way, participants will have a clear expectation that they will need to pay attention throughout the experiment to not risk losing their reward.
Another flavor of catch trials is to ask the same question twice but in a different way. You might for example ask someone’s age at the beginning and year of birth at the end. If a participant was trying to cheat, they will likely not be able to produce matching results.
Be careful to not overuse catch trials and try to frame and word these trials in a way that is not too accusatory as it’s important to maintain a level of trust between researcher and participant.
Most participants will have good intentions when taking part in your experiments. But in light of long, repetitive tasks, they might fall for the temptation to switch to autopilot to finish the study as quickly as possible. Simply asking participants for their honesty in a debrief questionnaire at the end of the study might work wonders. This questionnaire could ask participants about their level of attentiveness and engagement during the experiment, and could also ask them to report any instances of inattention or distraction. There is a high chance that many will say the truth and admit their slip. You can use this information to identify unengaged participants and to exclude their data from the analysis.

Another way to prevent this is to use a recognition task at the end of the experiment. In this task, participants would be shown a series of items that were presented earlier in the experiment, and they would be asked to identify which items were presented and which were not. This can help to ensure that participants were paying attention throughout the experiment and can serve as a more qualitative marker of data quality. Even if there are no obvious patterns of cheating (such as speeding), poor recall is a good indicator of non-attentive or even automated experiment completion.

The context of where you recruit participants for your studies matters. The motivations, incentives, and self-selection of participants will differ from platform to platform, and it will manifest in the overall quality of the data that you are receiving.
Pools like Amazon’s Mechanical Turk are notorious for being overrun with bots. Most of the studies offered on the website are simple surveys or repetitive tasks used to train machine learning models. Participants are generally there to earn money, and in an environment of low rewards and uninteresting tasks, they have the incentive to prioritize the quantity of surveys over the quality of responses.
Dedicated academic pools like Prolific or Testable Minds are different, as they cater to the specific needs tailored to the needs of academic researchers. The general quality of studies, the reward that can be earned, and earning limits ensure that participants’ incentives to deliver quality data are aligned with yours.
Going even further, the Verified Identity feature on Testable Minds, ensures that participants are unique and that they are who they say they are. This even further increases engagement and reduces the risk of fraud in online research. You can find our research poster on this topic here.
Find out more about our participant pool Testable Minds.